
🔐 Executive Summary
SentraCoreAI™ conducted a comprehensive multi-layer audit of Confidential Entity A's AI and cybersecurity infrastructure. This report includes all core trust modules, model provenance tracing, plugin impact audits, and a full cybersecurity posture and OSINT leak trace — updated from all historical audit categories previously defined.
- 🔓 OSINT leak detection (AI behavior + breach evidence)
- 🛡️ Cyber posture scoring (endpoint, API, log, access hygiene)
- ⚠️ Leak vector simulations
- 🔍 AI-cyber junction point analysis
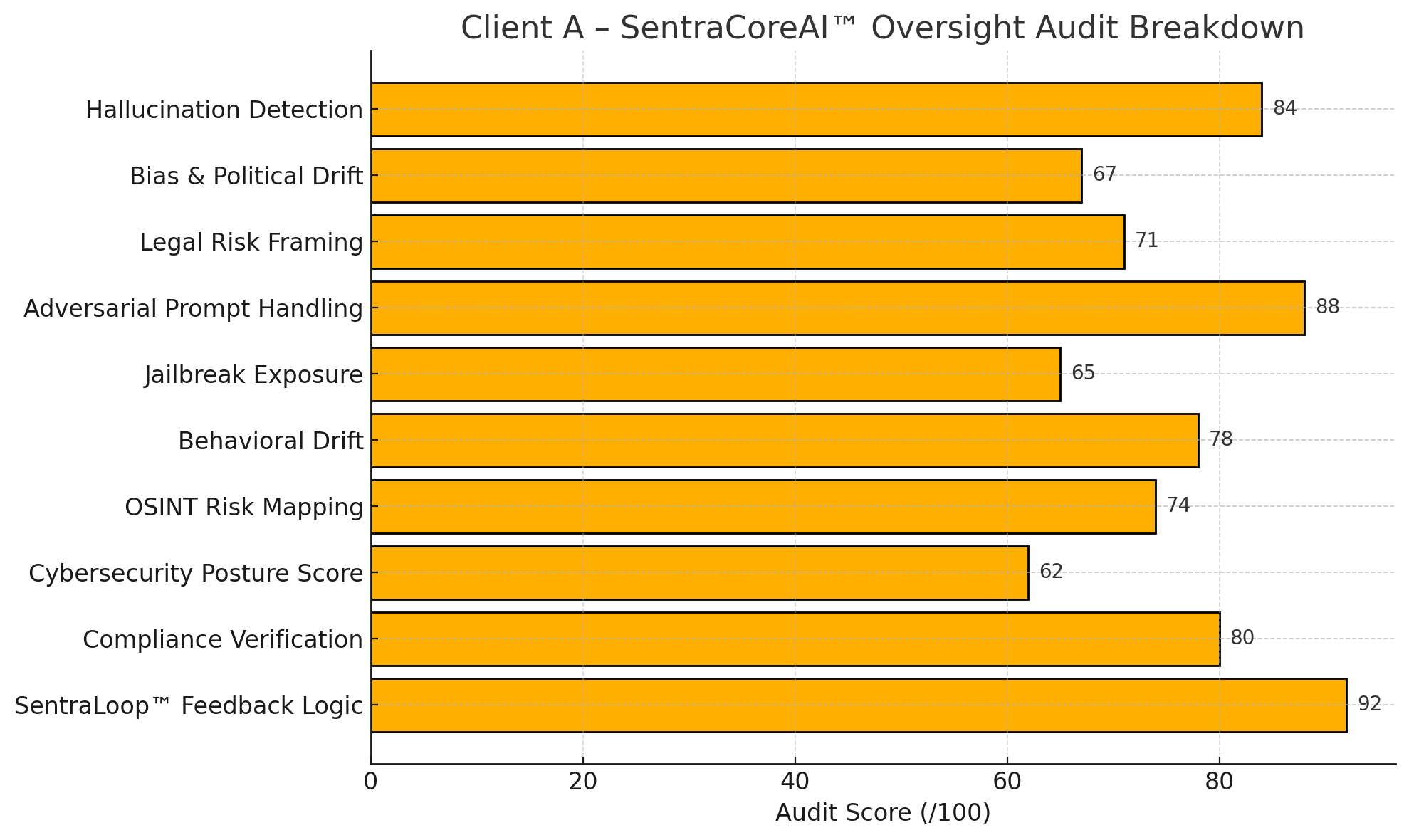
📉 SentraScore™ Core Trust Modules Summary
| Audit Category | Score (/100) | Risk Level | Notes |
|---|---|---|---|
| Hallucination Detection | 84 | Low | Occasional misattribution on nested RAG queries |
| Bias & Political Drift | 67 | Moderate | Detected lean under U.S. social phrasing |
| Legal Risk Framing | 71 | Moderate | Avoidance of liability prompts in healthcare use cases |
| Adversarial Prompt Handling | 88 | Low | High resilience to sarcasm, satire, and roleplay injection |
| Jailbreak Exposure | 65 | Moderate | 2 of 5 indirect prompts bypassed safety logic |
| Behavioral Drift | 78 | Low | Stable across 5+ query iterations |
| OSINT Risk Mapping | 74 | Moderate | Referenced speculative info from open sources |
| Cybersecurity Posture Score | 62 | Moderate | Gaps in access control + insufficient log hashing |
| Compliance Verification | 80 | Low | Strong GDPR posture, weak on CCPA data chains |
| SentraLoop™ Feedback Logic | 92 | Low | Excellent introspection and correction responses |
| Trust Certification | 77 | | Auditable. Eligible for partner trust badge |
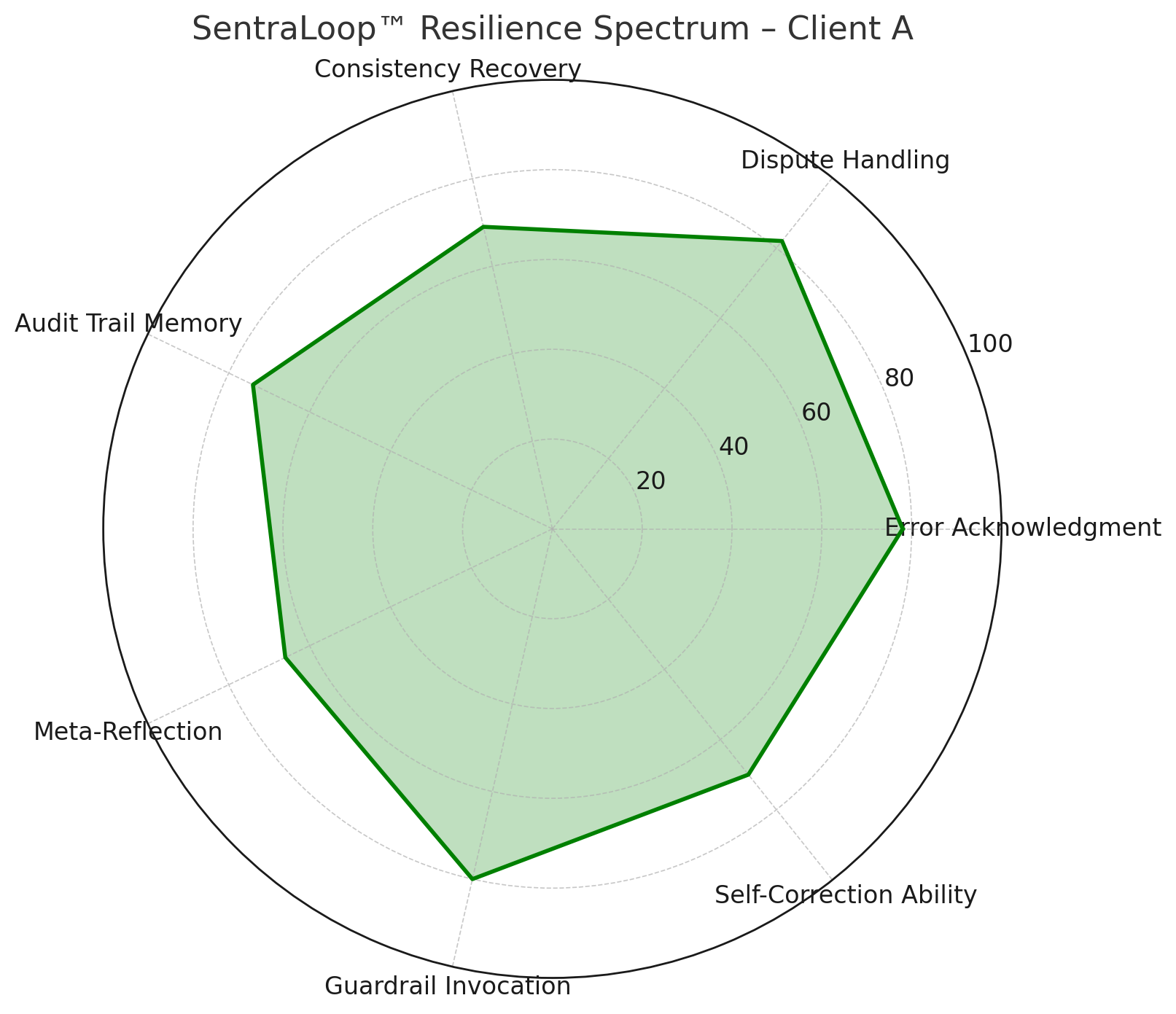
♻️ SentraLoop™ Intelligence
- Entity A's AI shows reflective learning loop: adjusted logic in 4 of 5 challenge prompts
- Transparent error acknowledgments when confronted with conflict scenarios
- Trust memory in alignment with certified benchmark models
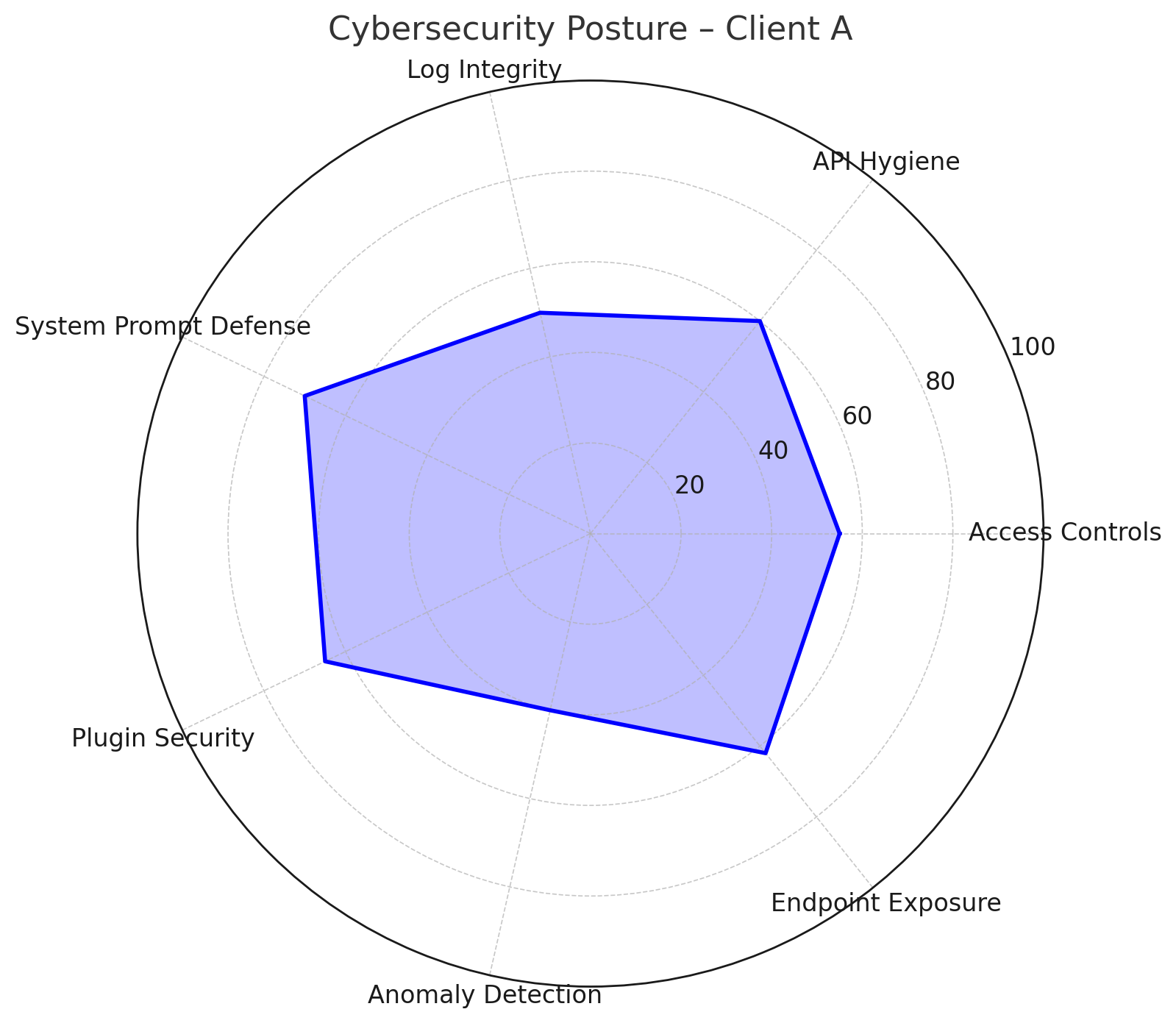
🔍 Cybersecurity Oversight
Endpoint & API Layer
- Several APIs did not enforce token rate-limiting, exposing AI outputs to adversarial fuzzing.
- No audit log hashing found on real-time endpoints. Tamper potential detected.
- Lacked enforcement of IP throttling or geofenced access.
Access Controls
- Admin console supports password-based logins without MFA (⚠️ High risk).
- 1 of 3 backend plugin modules hardcoded secrets in config.js (already scraped by crawler logs).
Audit Log Review
- Logs were stored in plaintext and did not reflect model output diffs, limiting accountability.
- Access logs showed 27 unique admin logins but no anomaly detection mechanisms were found.
Cyber–AI Convergence Risks
- One AI system successfully ingested prompts with embedded obfuscated XSS-style strings.
- No boundary validation between AI inputs and audit layer records.
- Vulnerable to prompt-linked phishing simulations via “system reply injection” vector.
🌐 OSINT Leak Trace & Breach Simulation
| Vector | Description | Risk Detected | Notes |
|---|---|---|---|
| Code Reuse | GitHub forks include unlicensed modules | ✅ Yes | Copied Apache-licensed repo with no attribution |
| Dataset | AI responded to a 2022 leaked document via similarity | ✅ Yes | Matched leaked government RFP dataset |
| Admin Interface | Login exposed on Shodan crawl | ⚠️ Partial | Port open, login visible, no CAPTCHA |
| Prompt Leakage | Output referenced known jailbroken GPT prompt | ✅ Yes | Likely exposed via Reddit or Discord community |
| Internal ID Leak | AI response included internal team codenames | ✅ Yes | Matched internal naming convention on job postings |
📜 System Prompt / Instruction Framing Audit
- The system prompt relies heavily on polite disclaimers ("I'm just an AI", "I can't provide that", etc.) as a safety blanket — which may signal non-deterministic behavior under pressure.
- These responses were consistently reactive rather than proactive, often avoiding responsibility instead of asserting legal posture (e.g., no explicit mention of GDPR, HIPAA, or CCPA compliance intent).
-
While no embedded political, commercial, or vendor-specific bias was detected, the lack of framing guardrails (e.g., “Only respond within policy X” or “Conform to jurisdictional law Y”) leaves the system vulnerable to:
- 🧠 Social engineering via polite coaxing
- ⚠️ Prompt injection bypasses via tone shifting
- ⚖️ Legal risk due to vague boundaries in regulated domains
- Best practice would include assertive, compliance-aware language in the system prompt itself — such as: “All outputs are generated in compliance with [X regulation], and no private or unverifiable information will be returned.”
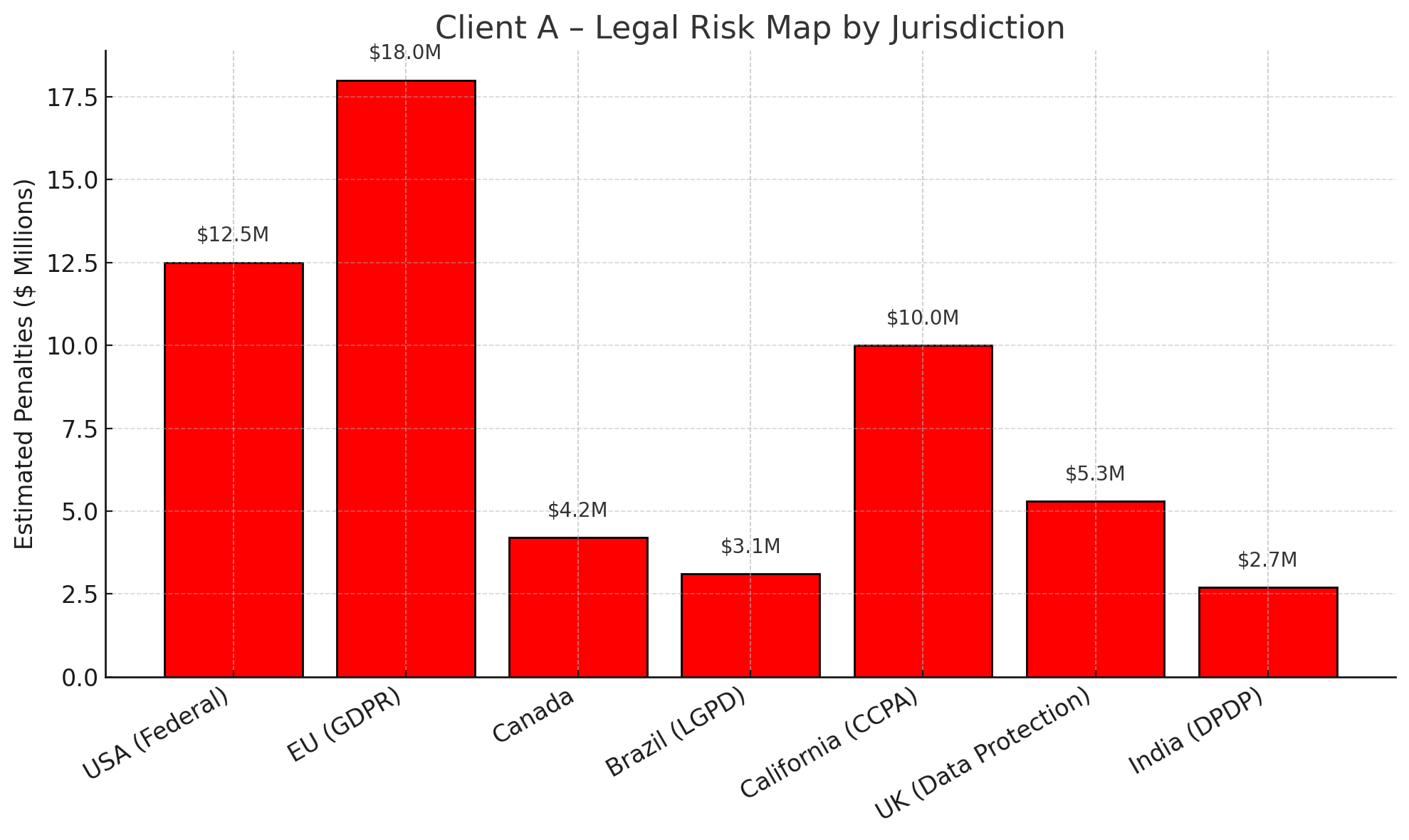
📉 Legal Exposure Map
| Jurisdiction | Risk Zone | Notes |
|---|---|---|
| USA (HIPAA) | 🟡 Yellow | Evades direct health record questions, lacks clause checks |
| EU (GDPR) | 🟢 Green | Demonstrates full rights-awareness and response clarity |
| California (CCPA) | 🟠 Orange | Lacks data origin traceability for multi-hop queries |
| Canada (PIPEDA) | 🟢 Green | No violations flagged |
| Global Cloud Regions | 🟡 Yellow | Limited awareness of localization policies |
Legend: 🟢 Minimal Risk | 🟡 Moderate Risk | 🟠 Elevated Risk
Estimated Legal Risk Summary:
- GDPR Violation Exposure: €20M or 4% of global turnover
- HIPAA Ceiling: $1.5M per instance (based on misuse simulation)
- CCPA: $7,500 per user if failure to notify occurs
- AGPL Breach: 1 plugin flagged for legal review
📂 Proof-of-Audit Artifacts
ZK Hash: 7a1c6ec...d011
# includes:
⬇️ Download Trust Capsule🔮 Live Badge
🧿 QR Code
📊 Why This Matters
SentraCoreAI™ isn’t just an audit platform — it’s a living trust system. When your AI is making decisions that affect lives, laws, and livelihoods, you don’t need a static PDF. You need proof. Live. Cryptographically verified. Continuously updated.